Zooniverse campaign
Summary
The present repository showcases the organization
of a Zooniverse campaign using ChildProject and DataLad.
Zooniverse is a crowd-sourcing platform
that may be used for large-scale annotation tasks. The ExElang book provides examples of research goals for which Zooniverse may be useful.
The present campaign requires citizens to listen to 500 ms audio clips
and then to perform the following tasks:
- Decide whether they hear speech from either a Baby, a Child, an Adolescent, an Adult, or no speech.
- Guess the gender of Adolescent or Adult speakers.
- Classify the type of sound among four categories (Canonical, Non-Canonical, Laughing, Crying).
Workflow
- We used DataLad to manage this campaign (installation instructions here).
- The primary dataset (containing the audio and the metadata)
was included in this repository as a subdataset. It was structured according to ChildProject's format.
- ChildProject was used to generate the samples, to upload the audio chunks to zooniverse, and to retrieve the classification (installation instructions here).
This repository contains all the scripts that we used to implement this workflow.
You are welcome to re-use this code and adapt it to your needs.
Repository structure
annotations contains annotations built from the classifications retrieved from Zooniverse.classifications contains the classifications retrieved from Zooniverse.samples contains the samples that were selected as well as the chunks generated from them.vandam-data is a subdataset containing VanDam Daylong corpus, structed according to ChildProject's format — this is very important as it allows to use all the features of ChildProject that will be used next.
Preparing samples
The first step is to prepare the samples to be annotated; this includes choosing the portions of audio to annotate, and then extracting audio files from these portions.
See this issue for examples of sampling strategies that have been used or considered.
Many of them involve splitting the audio in short chunks in order to preserve privacy. However, this technique may not be suited for certain annotation tasks (e.g. for semantics).
Sampling
Sampling consists in selecting which portions of the recordings should be annotated by humans.
It can be done through using the samplers provided in the ChildProject package.
Here, we sample 50 vocalizations per recording among all those detected and attributed to the key child (CHI) or a female adult (FEM) by the Voice Type Classifier:
# download VTC annotations
datalad get vandam-data/annotations/vtc/converted
# sample random CHI and FEM vocalizations from these annotations
child-project sampler vandam-data samples/chi_fem/ random-vocalizations \
--annotation-set vtc \
--target-speaker-type CHI FEM \
--sample-size 50 \
--by recording_filename
The sampler produces a CSV dataframe as samples/chi_fem/segments_YYYYMMDD_HHMMSS.csv, e.g. samples/chi_fem/segments_20210716_184443.csv.
Preparing the chunks for Zooniverse
After the samples have been generated, they have to be extracted from the audio and uploaded to Zooniverse, which can be done with ChildProject's extract-chunks function.
However, these samples may contain private information about the participants. Therefore, they cannot be shared as is on a public crowd-sourcing platform. We therefore configure extract-chunks to split these samples into 500ms chunks, which will be classified in random order, thus preventing the recovery of sensitive information by the contributors:
datalad get vandam-data/recordings/converted/standard
child-project zooniverse extract-chunks vandam-data \
--keyword chi_fem \
--chunks-length 500 \
--segments samples/chi_fem/segments_20210716_184443.csv \
--destination samples/chi_fem/chunks \
--profile standard
This will extract the audio chunks into samples/chi_fem/chunks/chunks/ and write a metadata file into samples/chi_fem/chunks (in our case, as samples/chi_fem/chunks/chunks_20210716_191944.csv).
See ChildProject's documentation for more information about the Zooniverse pipeline.
Uploading audio chunks to Zooniverse
Once the chunks have been extracted, the next step is to upload them to Zooniverse.
Note that due to quotas, it is recommended to upload only a few at time (e.g. 1000 per day).
You will need to provide the numerical id of your Zooniverse project. Instructions to create a Zooniverse project are available here.
You will also need to set Zooniverse credentials as environment variables:
export ZOONIVERSE_LOGIN=""
export ZOONIVERSE_PWD=""
export PROJECT_ID=14957
child-project zooniverse upload-chunks \
--chunks samples/chi_fem/chunks/chunks_20210716_191944.csv \
--project-id $PROJECT_ID \
--set-name vandam_chi_fem \
--amount 1000
This will display a message for each chunk:
...
uploading chunk BN32_010007.mp3 (25153080,25153580)
uploading chunk BN32_010007.mp3 (45016146,45016646)
uploading chunk BN32_010007.mp3 (46794141,46794641)
uploading chunk BN32_010007.mp3 (14107752,14108252)
uploading chunk BN32_010007.mp3 (35709983,35710483)
uploading chunk BN32_010007.mp3 (45433933,45434433)
uploading chunk BN32_010007.mp3 (35711483,35711983)
uploading chunk BN32_010007.mp3 (38737938,38738438)
uploading chunk BN32_010007.mp3 (24586156,24586656)
uploading chunk BN32_010007.mp3 (15556956,15557456)
uploading chunk BN32_010007.mp3 (28439601,28440101)
uploading chunk BN32_010007.mp3 (27317629,27318129)
uploading chunk BN32_010007.mp3 (38391252,38391752)
...
The subject set and its subjects (i.e. the chunks) now appears in the project:
Retrieving classifications
The classifications performed by citizens on Zooniverse for this project can be retrieved with ChildProject's retrieve-classifications command:
child-project zooniverse retrieve-classifications \
--destination classifications/classifications.csv \
--project-id $PROJECT_ID
$ head classifications/classifications.csv
id,user_id,subject_id,task_id,answer_id,workflow_id,answer
335442480,2202359,61513545,T1,4,17576,Junk
335442502,2202359,61513542,T1,4,17576,Junk
335442523,2202359,61513540,T1,4,17576,Junk
335442614,2202359,61513546,T1,4,17576,Junk
335442630,2202359,61513544,T1,4,17576,Junk
335443247,2221541,61513546,T1,4,17576,Junk
335443443,2202359,61513544,T1,4,17576,Junk
335450309,1078249,61513540,T1,4,17576,Junk
335457868,2202359,61514279,T1,4,17576,Junk
The output contains no information related to the metadata of the input dataset, which is the desired behavior (Zooniverse should not store any data that might compromise the privacy of the participants)
It also contains all the classifications for this project, including those for data outside of the current campaign.
As a result, these data alone cannot be exploited and they have to be matched to the chunks metadata.
Matching classifications back to the metadata
Classifications can be matched to the original metadata (the recording from which the clips were extracted, the timestamps of the clips, etc.) manually, but it is possible to retrieve the classifications from Zooniverse and match them with their metadata at the same time with ChildProject:
child-project zooniverse retrieve-classifications \
--destination classifications/classifications.csv \
--project-id $PROJECT_ID \
--chunks samples/chi_fem/chunks/chunks*.csv
Now, only relevant chunks are returned, and they are associated to all corresponding metadata:
| id |
user_id |
subject_id |
task_id |
answer_id |
workflow_id |
answer |
index |
recording_filename |
onset |
offset |
segment_onset |
segment_offset |
wav |
mp3 |
date_extracted |
uploaded |
project_id |
subject_set |
zooniverse_id |
keyword |
| 346474371 |
2202359.0 |
64210633 |
T1 |
4 |
17576 |
Junk |
38 |
BN32_010007.mp3 |
24587156 |
24587656 |
24584902 |
24588410 |
BN32_010007_24587156_24587656.wav |
BN32_010007_24587156_24587656.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210633 |
chi_fem |
| 346474611 |
2202359.0 |
64210607 |
T1 |
4 |
17576 |
Junk |
30 |
BN32_010007.mp3 |
14108752 |
14109252 |
14107993 |
14109011 |
BN32_010007_14108752_14109252.wav |
BN32_010007_14108752_14109252.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210607 |
chi_fem |
| 346474648 |
2202359.0 |
64210647 |
T1 |
4 |
17576 |
Junk |
43 |
BN32_010007.mp3 |
4713603 |
4714103 |
4713263 |
4714944 |
BN32_010007_4713603_4714103.wav |
BN32_010007_4713603_4714103.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210647 |
chi_fem |
| 346474683 |
2202359.0 |
64210890 |
T1 |
4 |
17576 |
Junk |
125 |
BN32_010007.mp3 |
4713103 |
4713603 |
4713263 |
4714944 |
BN32_010007_4713103_4713603.wav |
BN32_010007_4713103_4713603.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210890 |
chi_fem |
| 346474902 |
2202359.0 |
64210872 |
T1 |
4 |
17576 |
Junk |
119 |
BN32_010007.mp3 |
39329854 |
39330354 |
39328511 |
39331697 |
BN32_010007_39329854_39330354.wav |
BN32_010007_39329854_39330354.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210872 |
chi_fem |
| 346475101 |
2202359.0 |
64210613 |
T1 |
4 |
17576 |
Junk |
32 |
BN32_010007.mp3 |
4149238 |
4149738 |
4148967 |
4149510 |
BN32_010007_4149238_4149738.wav |
BN32_010007_4149238_4149738.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210613 |
chi_fem |
| 346475237 |
2202359.0 |
64210774 |
T1 |
4 |
17576 |
Junk |
86 |
BN32_010007.mp3 |
17157819 |
17158319 |
17157511 |
17158127 |
BN32_010007_17157819_17158319.wav |
BN32_010007_17157819_17158319.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210774 |
chi_fem |
| 346474475 |
2202359.0 |
64210728 |
T1 |
0 |
17576 |
Baby |
70 |
BN32_010007.mp3 |
37978055 |
37978555 |
37978100 |
37979011 |
BN32_010007_37978055_37978555.wav |
BN32_010007_37978055_37978555.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210728 |
chi_fem |
| 346474475 |
2202359.0 |
64210728 |
T3 |
1 |
17576 |
Non-Canonical |
70 |
BN32_010007.mp3 |
37978055 |
37978555 |
37978100 |
37979011 |
BN32_010007_37978055_37978555.wav |
BN32_010007_37978055_37978555.mp3 |
2021-07-16 19:19:44 |
True |
14957 |
vandam_chi_fem |
64210728 |
chi_fem |
Importing classifications into the source dataset
Once the classifications have been recovered, they can be used to enrich the source dataset with more annotations.
While this step may depend a lot on the type of annotation that you are doing, this repository provides an example.
The feed-annotations script does just that. It can be run with:
python annotations/feed-annotations.py classifications/classifications.csv
The classifications are then imported into the vandam-data subdataset using ChildProject:
$ tail -n 1 vandam-data/metadata/annotations.csv
zoo,BN32_010007.mp3,0,0,50464512,BN32_010007.csv,csv,,BN32_010007_0_50464512.csv,2021-07-19 11:14:58,,0.0.1
In case several users have classified the same chunks, the majority choice is retained. You can have a look at the source of the script to see how that works - or to adapt it to your needs!
Other strategies can be considered; in previous work, Semenzin et al. (2020) have reconstructed the original segments by combining the classifications of the 500 ms chunks, while Cychosz et al. (2021) used the classifications of the individual chunks without reconstruction.
Comparing Zooniverse annotations with other annotations
Once the annotations have been imported into the original dataset, you can use all the functionalities of the ChildProject package e.g. for reliability estimations.
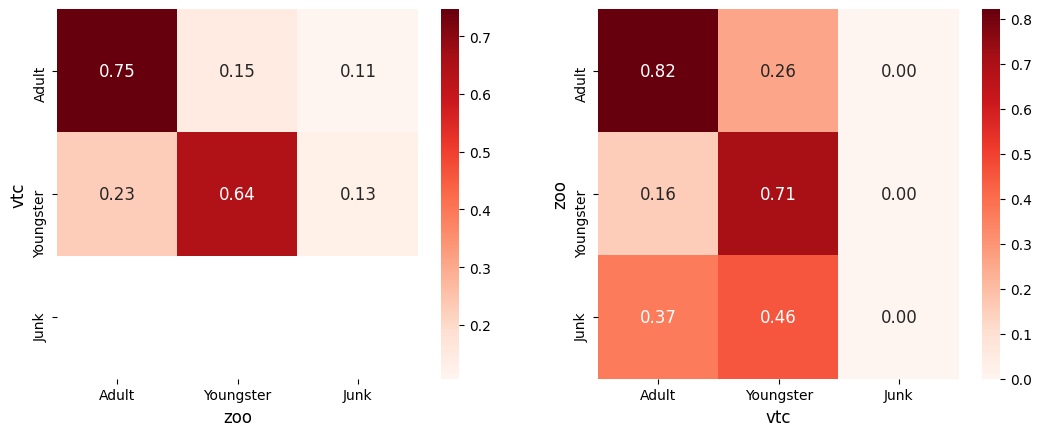
For instance, let's day we'd like to test the ability of the VTC to distinguish children from adults, based on the classifications retrieved with Zooniverse.
The compare does just that (look at the source and try it by yourself!):
python annotations/compare.py
Which will output:
Going big
This example only contains around a hundred subjects extracted from a sole recording.
Real-life projects usually involve much more data - typically tens of thousands of subjects.
In order to go big, we advise you of the following:
- Ask Zooniverse for increased subjects quota.
- If you are using a version control system such as git/DataLad, you may not want to commit the audio chunks. This can be avoided with appropriate rules in a
.gitignore file. Versioning too many files within one repository may cripple it and render operations much slower. Also, provided the metadata for the selected chunks and the original recordings are properly stored and backed-up, the audio chunks can be extracted again at any later time if necessary.
- Some operations such as sampling or extracting chunks may be demanding for large datasets. We recommend performing this step on a cluster using several CPU cores. The ChildProject provides a
--threads option for parallel processing.

