

100 changed files with 232 additions and 0 deletions
+ 136
- 0
README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
extra/zoo1.png
{kind=link}
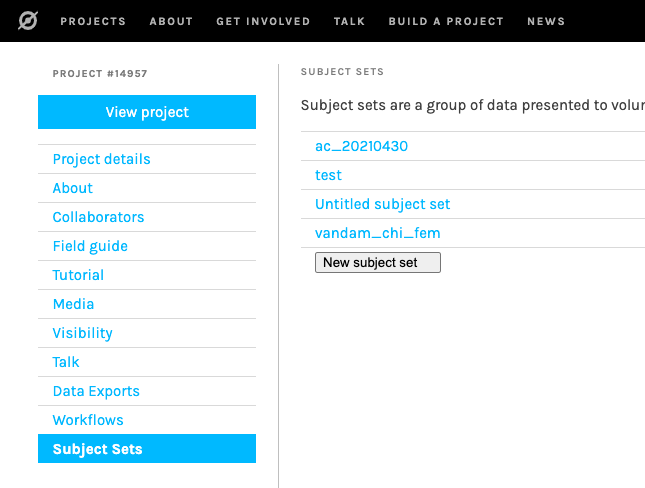
BIN
extra/zoo2.png
{kind=link}

+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13045173_13045673.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13045173_13045673.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13045673_13046173.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13045673_13046173.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13458929_13459429.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13458929_13459429.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13459429_13459929.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13459429_13459929.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13968039_13968539.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13968039_13968539.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13968539_13969039.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13968539_13969039.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13969039_13969539.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_13969039_13969539.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14059422_14059922.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14059422_14059922.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14059922_14060422.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14059922_14060422.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14107752_14108252.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14107752_14108252.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14108252_14108752.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14108252_14108752.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14108752_14109252.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14108752_14109252.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14488435_14488935.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14488435_14488935.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14523226_14523726.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14523226_14523726.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14523726_14524226.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_14523726_14524226.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15556956_15557456.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15556956_15557456.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15756570_15757070.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15756570_15757070.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15757070_15757570.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15757070_15757570.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15957309_15957809.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15957309_15957809.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15957809_15958309.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_15957809_15958309.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_16523357_16523857.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_16523357_16523857.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_17157319_17157819.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_17157319_17157819.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_17157819_17158319.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_17157819_17158319.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_22739523_22740023.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_22739523_22740023.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_22740023_22740523.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_22740023_22740523.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24584656_24585156.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24584656_24585156.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24585156_24585656.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24585156_24585656.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24585656_24586156.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24585656_24586156.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24586156_24586656.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24586156_24586656.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24586656_24587156.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24586656_24587156.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24587156_24587656.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24587156_24587656.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24587656_24588156.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24587656_24588156.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24588156_24588656.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24588156_24588656.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24936946_24937446.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24936946_24937446.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24937446_24937946.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_24937446_24937946.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25153080_25153580.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25153080_25153580.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25153580_25154080.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25153580_25154080.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25325193_25325693.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25325193_25325693.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25325693_25326193.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_25325693_25326193.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_26905953_26906453.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_26905953_26906453.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_26906453_26906953.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_26906453_26906953.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_27317629_27318129.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_27317629_27318129.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_28439101_28439601.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_28439101_28439601.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_28439601_28440101.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_28439601_28440101.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_28440101_28440601.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_28440101_28440601.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_3231280_3231780.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_3231280_3231780.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_3231780_3232280.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_3231780_3232280.wav
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_33310617_33311117.mp3
|
||
|
||
+ 1
- 0
samples/chi_fem/chunks/chunks/BN32_010007_33310617_33311117.wav
|
||
|
||