|
|
@@ -379,7 +379,7 @@ best_metric$icc_child_id=round(best_metric$icc_child_id,2)
|
|
|
```
|
|
|
|
|
|
|
|
|
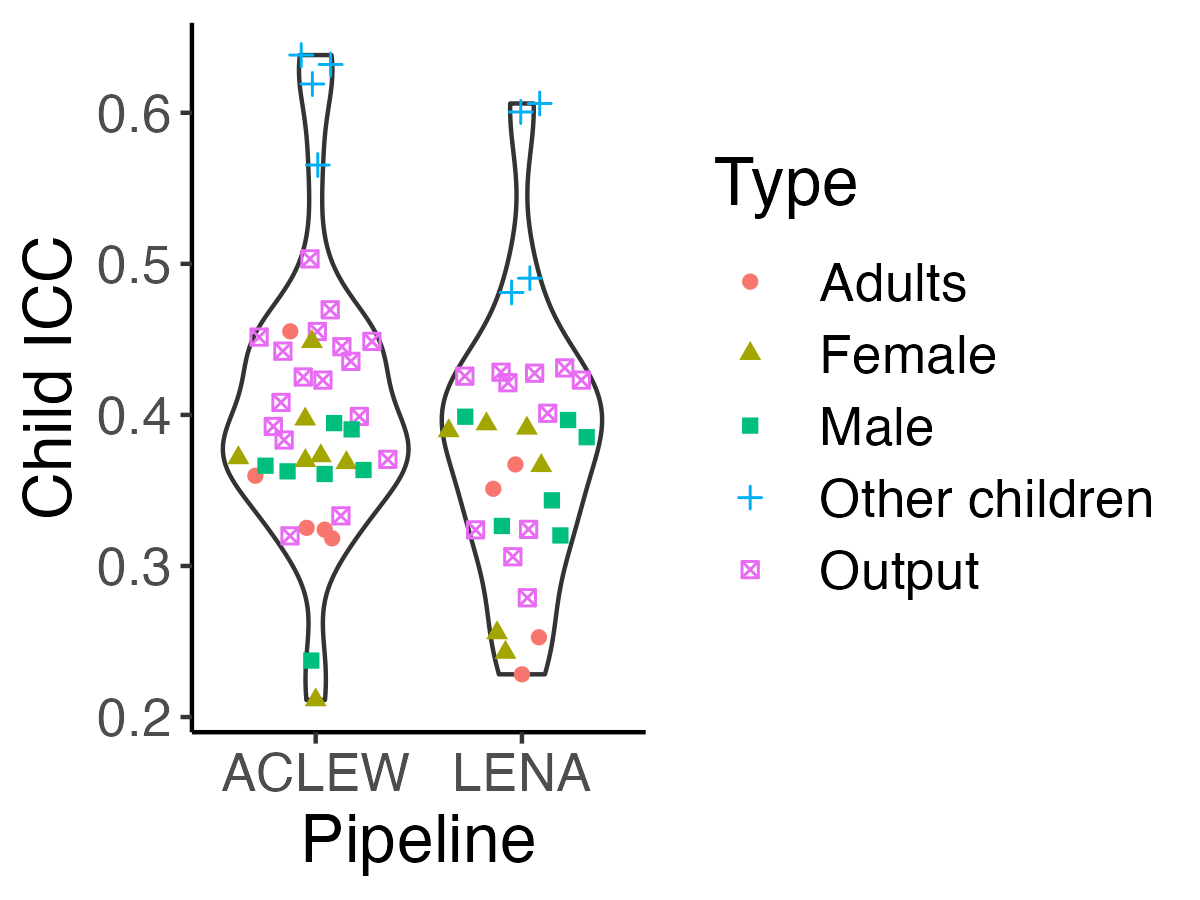
-> Figure 5 shows the distribution of Child ICC across all `r dim(df.icc.mixed)[1]` metrics, separately for each pipeline. The majority of measures had Child ICCs between .3 and .5. `r sum(df.icc.mixed$icc_child_id > .5)` measures had Child ICCs higher or equal to .5. Surprisingly, the top 6 metrics in terms of Child ICC corresponded to the "other child" category, known to have the worst accuracy according to previous analyses (Cristia et al., 2020). In an analysis fully reported in the SM, we find some evidence that this may be due to the presence versus absence of siblings. The next metric with the highest Child ICC corresponded to an output measure, namely the total vocalization duration per hour extracted from ACLEW annotations (`r best_metric[best_metric$Type=="Output",c("metric","data_set")]`), with a Child ICC of `r best_metric[best_metric$Type=="Output","icc_child_id"]`. Among adult metrics, the average vocalization duration for female vocalizations for ACLEW (`r best_metric[best_metric$Type=="Female",c("metric","data_set")]`) and the ACLEW equivalent of CTC had the highest Child ICC (`r best_metric[best_metric$Type=="Female","icc_child_id"]` and `r best_metric[best_metric$Type=="Adults","icc_child_id"]`, respectively).
|
|
|
+> Figure 5 shows the distribution of Child ICC across all `r dim(df.icc.mixed)[1]` metrics, separately for each pipeline. The majority of measures had Child ICCs between .3 and .5. `r sum(df.icc.mixed$icc_child_id > .5)` measures had Child ICCs higher or equal to .5. Surprisingly, the top 6 metrics in terms of Child ICC corresponded to the "other child" category, known to have the worst accuracy according to previous analyses (Cristia et al., 2020). In an analysis fully reported in supplementary materials (SM K), we find some evidence that this may be due to the presence versus absence of siblings. The next metric with the highest Child ICC corresponded to an output measure, namely the total vocalization duration per hour extracted from ACLEW annotations (`r best_metric[best_metric$Type=="Output",c("metric","data_set")]`), with a Child ICC of `r best_metric[best_metric$Type=="Output","icc_child_id"]`. Among adult metrics, the average vocalization duration for female vocalizations for ACLEW (`r best_metric[best_metric$Type=="Female",c("metric","data_set")]`) and the ACLEW equivalent of CTC had the highest Child ICC (`r best_metric[best_metric$Type=="Female","icc_child_id"]` and `r best_metric[best_metric$Type=="Adults","icc_child_id"]`, respectively).
|
|
|
|
|
|
## SM K: Are high Child ICCs for "other child" measures due to number or presence of siblings? (Exploration)
|
|
|
|
|
|
@@ -429,7 +429,7 @@ As in the sibling number analysis, the full model was singular, so we fitted a N
|
|
|
|
|
|
Among ACLEW measures, a fair number of them come from VCM, a module that classifies child vocalizations in terms of vocal maturity types into cry, canonical, and non-canonical categories. In unpublished analyses, we have found that VCM labels are inaccurate when compared to human labels of the same vocalizations, relatively to other metrics. In this analysis, we checked whether VCM-derived measures had lower Child ICC than other ACLEW measures. As shown in the next Figure, this was not the case: Some output measures from the ACLEW pipeline have lower Child ICC than VCM ones.
|
|
|
|
|
|
-```{r}
|
|
|
+```{r,fig.cap="Figure SM L. Violin plot reflecting the distribution of Child ICC for ACLEW VCM versus other ACLEW or LENA metrics."}
|
|
|
vcm_type<-rep("Other ACLEW",dim(df.icc.mixed)[1])
|
|
|
vcm_type[df.icc.mixed$data_set=="lena"]<-"LENA"
|
|
|
vcm_type[grep("lp",df.icc.mixed$metric)]<-"ACLEW VCM"
|
|
|
@@ -449,13 +449,13 @@ panel.background = element_blank(), legend.key=element_blank(), axis.line = elem
|
|
|
|
|
|
## SM M: Code to reproduce Figure 5
|
|
|
|
|
|
-```{r icc-allexp-fig5, echo=F,fig.width=4, fig.height=3,fig.cap="Figure 5 (reproduced). Violin plot reflecting the distribution of Child ICC."}
|
|
|
+```{r icc-allexp-fig5, echo=F,fig.width=6, fig.height=3,fig.cap="Figure 5 (reproduced). Violin plot reflecting the distribution of Child ICC."}
|
|
|
|
|
|
|
|
|
fig5 <- ggplot(df.icc.mixed, aes(y = icc_child_id, x = toupper(data_set))) +
|
|
|
geom_violin(alpha = 0.5) +
|
|
|
geom_quasirandom(aes(colour = Type,shape = Type)) +
|
|
|
- labs( y = "Child ICC",x="Pipeline") + theme(text = element_text(size = 20)) +
|
|
|
+ labs( y = "Child ICC",x="Pipeline") + theme(text = element_text(size = 16)) +
|
|
|
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
|
|
|
panel.background = element_blank(), legend.key=element_blank(), axis.line = element_line(colour = "black"))
|
|
|
|
|
|
@@ -488,7 +488,7 @@ rownames(msds_p)<-msds_p$Group.1
|
|
|
```
|
|
|
|
|
|
|
|
|
-> Next, we explored how similar Child ICCs were across different talker types and pipelines. We fit a linear model with the formula $lm(icc\_child\_id ~ type * pipeline)$, where type indicates whether the measure pertained to the key child, (female/male) adults, other children; and pipeline LENA or ACLEW. The model was overall significant (F(`r round(reg_sum$fstatistic["dendf"],2)`) = `r round(reg_sum$fstatistic["value"],2)`, p < .001). We found an adjusted R-squared of `r round(reg_sum$adj.r.squared*100)`%, suggesting much of the variance across Child ICCs was explained by these factors. A Type 3 ANOVA on this model revealed type was a signficant predictor (F(`r reg_anova["Type","Df"]`) = `r round(reg_anova["Type","F value"],1)`, p<.001), as was pipeline (F(`r reg_anova["data_set","Df"]`) = `r round(reg_anova["data_set","F value"],1)`, p = `r round(reg_anova["data_set","Pr(>F)"],3)`); the interaction between type and pipeline was not significant. The main effect of type emerged because output metrics tended to have higher Child ICC (`r msds["Output","x"]`) than those associated to adults in general (`r msds["Adults","x"]`), females (`r msds["Female","x"]`), and males (`r msds["Male","x"]`); whereas those associated with other children had even higher Child ICCs (`r msds["Other children","x"]`). The main effect of pipeline arose because of slightly higher Child ICCs for the ACLEW metrics (`r msds_p["aclew","x"]`) than for LENA metrics (`r msds_p["lena","x"]`).
|
|
|
+> Next, we explored how similar Child ICCs were across different talker types and pipelines. We fit a linear model with the formula $lm(icc\_child\_id ~ type * pipeline)$, where type indicates whether the measure pertained to the key child, (female/male) adults, other children; and pipeline LENA or ACLEW. The model was overall significant (F(`r round(reg_sum$fstatistic["dendf"],2)`) = `r round(reg_sum$fstatistic["value"],2)`, p < .001). We found an adjusted R-squared of `r round(reg_sum$adj.r.squared*100)`%, suggesting much of the variance across Child ICCs was explained by these factors. A Type 3 ANOVA on this model revealed type was a significant predictor (F(`r reg_anova["Type","Df"]`) = `r round(reg_anova["Type","F value"],1)`, p<.001), as was pipeline (F(`r reg_anova["data_set","Df"]`) = `r round(reg_anova["data_set","F value"],1)`, p = `r round(reg_anova["data_set","Pr(>F)"],3)`); the interaction between type and pipeline was not significant. The main effect of type emerged because output metrics tended to have higher Child ICC (`r msds["Output","x"]`) than those associated to adults in general (`r msds["Adults","x"]`), females (`r msds["Female","x"]`), and males (`r msds["Male","x"]`); whereas those associated with other children had even higher Child ICCs (`r msds["Other children","x"]`). The main effect of pipeline arose because of slightly higher Child ICCs for the ACLEW metrics (`r msds_p["aclew","x"]`) than for LENA metrics (`r msds_p["lena","x"]`).
|
|
|
|
|
|
|
|
|
## SM O: Code to reproduce Table 4
|
|
|
@@ -569,7 +569,10 @@ reg_anova_age_icc=Anova(age_icc)
|
|
|
|
|
|
```
|
|
|
|
|
|
-> To interrogate these results statistically, and assess whether Child ICCs tended to be higher or lower in certain age bins, we fit a linear model with the formula $lm(Child_ICC ~ type * pipeline * age_bin)$. The model was overall significant (F(`r round(reg_sum_age_icc$fstatistic["dendf"],2)`) = `r round(reg_sum_age_icc$fstatistic["value"],2)`, p < .001). We found an adjusted R-squared of `r round(reg_sum_age_icc$adj.r.squared*100)`%, suggesting this model explained about a third of the variance in Child ICC. A Type 3 ANOVA on this model revealed type was a signficant predictor (F(`r reg_anova["Type","Df"]`) = `r round(reg_anova["Type","F value"],1)`, p<.001), whereas as was pipeline (F(`r reg_anova["data_set","Df"]`) = `r round(reg_anova["data_set","F value"],1)`, p = `r round(reg_anova["data_set","Pr(>F)"],3)`); the interaction between type and pipeline was not significant.
|
|
|
+> To interrogate these results statistically, and assess whether Child ICCs tended to be higher or lower in certain age bins, we fit a linear model with the formula $lm(Child\_ICC ~ type * pipeline * age\_bin)$. The model was overall significant (F(`r round(reg_sum_age_icc$fstatistic["dendf"],2)`) = `r round(reg_sum_age_icc$fstatistic["value"],2)`, p < .001). We found an adjusted R-squared of `r round(reg_sum_age_icc$adj.r.squared*100)`%, suggesting this model explained more than a third of the variance in Child ICC. A Type 3 ANOVA on this model revealed that the interactions between type and pipeline, pipeline and age, and the three-way interaction (type, pipeline, age) were not significant. However, both the type by age bin interaction (F(`r reg_anova_age_icc["Type:age_bin","Df"]`) = `r round(reg_anova_age_icc["Type:age_bin","F value"],1)`, p < .001) and the three main effects were significant (
|
|
|
+type: F(`r reg_anova_age_icc["Type","Df"]`) = `r round(reg_anova_age_icc["Type","F value"],1)`, p < .001;
|
|
|
+age: F(`r reg_anova_age_icc["age_bin","Df"]`) = `r round(reg_anova_age_icc["age_bin","F value"],1)`, p < .001;
|
|
|
+pipeline: F(`r reg_anova_age_icc["data_set","Df"]`) = `r round(reg_anova_age_icc["age_bin","F value"],1)`, p = .01).
|
|
|
|
|
|
See table below for results of the Type 3 ANOVA.
|
|
|
|
|
|
@@ -627,7 +630,7 @@ ggsave("fig7.png", plot = fig7, width = 4, height = 4, units = "in")
|
|
|
## SM U: Code to reproduce Figure 8
|
|
|
|
|
|
|
|
|
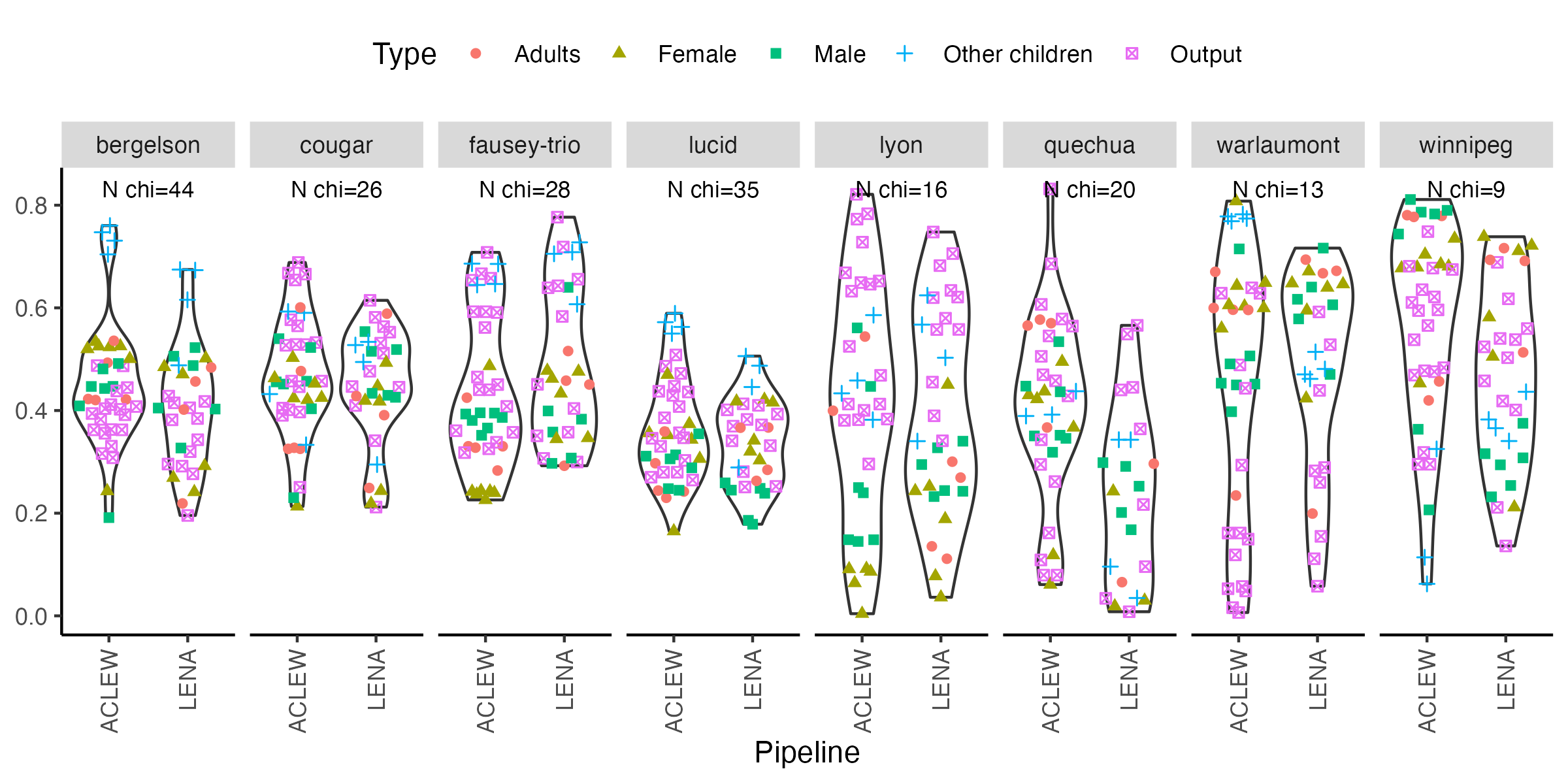
-```{r icc-bycor-fig8, echo=F,fig.width=4, fig.height=4,fig.cap="Figure 8 (reproduced). Child ICC by metric type and pipeline, when considering each corpus separately."}
|
|
|
+```{r icc-bycor-fig8, echo=F,fig.width=8, fig.height=4,fig.cap="Figure 8 (reproduced). Child ICC by metric type and pipeline, when considering each corpus separately."}
|
|
|
|
|
|
facet_labels_chi = paste0("N chi=",chiXcor)
|
|
|
|
|
|
@@ -647,7 +650,7 @@ panel.background = element_blank(), legend.key=element_blank(), axis.line = elem
|
|
|
|
|
|
fig8
|
|
|
|
|
|
-ggsave("fig8.png", plot = fig8, width = 4, height = 4, units = "in")
|
|
|
+ggsave("fig8.png", plot = fig8, width = 8, height = 4, units = "in")
|
|
|
|
|
|
```
|
|
|
|
|
|
@@ -678,7 +681,7 @@ kable(round(reg_anova_cor_icc,2),caption="Type 3 ANOVA on model attempting to ex
|
|
|
|
|
|
## SM W: Code to reproduce Figure 9
|
|
|
|
|
|
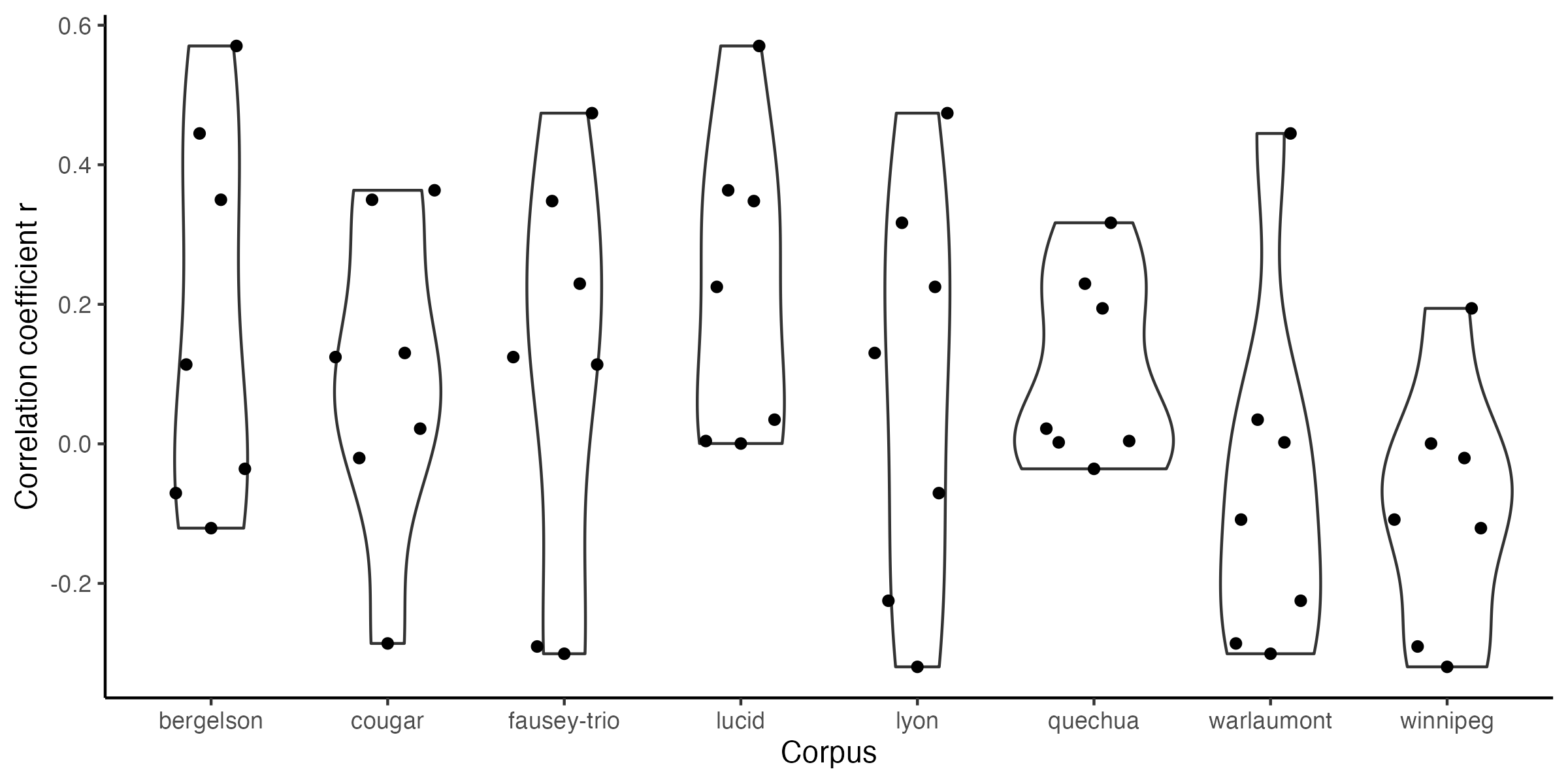
-```{r icc-bycor-fig9, echo=F,fig.width=4, fig.height=4,fig.cap="Figure 9 (reproduced). Correlations in Child ICC across corpora."}
|
|
|
+```{r icc-bycor-fig9, echo=F,fig.width=8, fig.height=4,fig.cap="Figure 9 (reproduced). Correlations in Child ICC across corpora."}
|
|
|
|
|
|
|
|
|
|
|
|
@@ -707,7 +710,7 @@ panel.background = element_blank(), legend.key=element_blank(), axis.line = elem
|
|
|
|
|
|
fig9
|
|
|
|
|
|
-ggsave("fig9.png", plot = fig9, width = 4, height = 4, units = "in")
|
|
|
+ggsave("fig9.png", plot = fig9, width = 8, height = 4, units = "in")
|
|
|
```
|
|
|
|
|
|
## SM X: Code to reproduce text in the Discussion section
|


{kind=link}
{kind=link}
{kind=link}