
README.md 6.3 KB

EEGmanypipelines analysis
a_eegmp_calculate_erp_tfr
- 50, 100, 150 Hz notch filter
- CSD transform implemented via spherical splines using eeg1005 template
- time-frequency transform using superlets
- TFR: single-trial log10, no baseline
- ERP: single-trial baseline -200:0 ms subtraction
- condition averaging
b_scenecat_n1_bl
Assess effect of scene novelty on visual N1 peak amplitude.
Figure 1a:
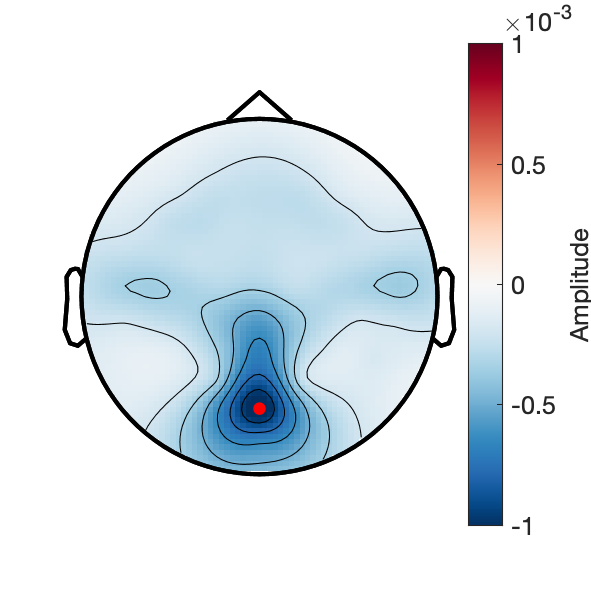
Figure 1b:
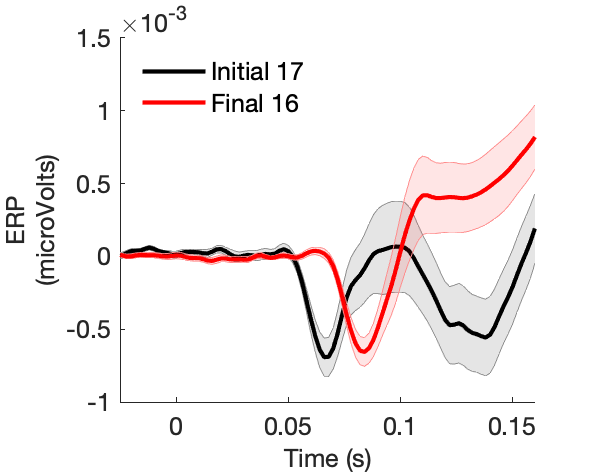
Figure 1c:
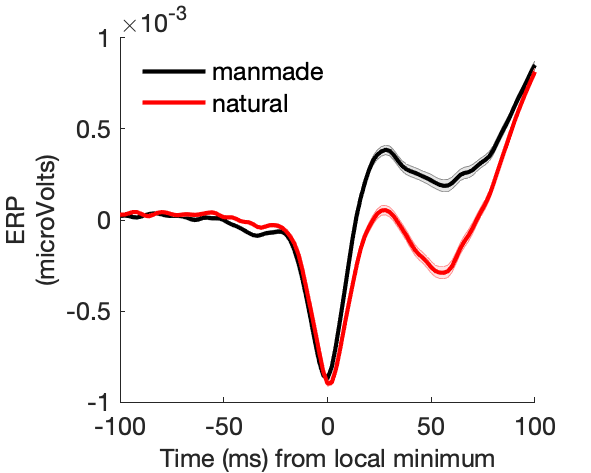
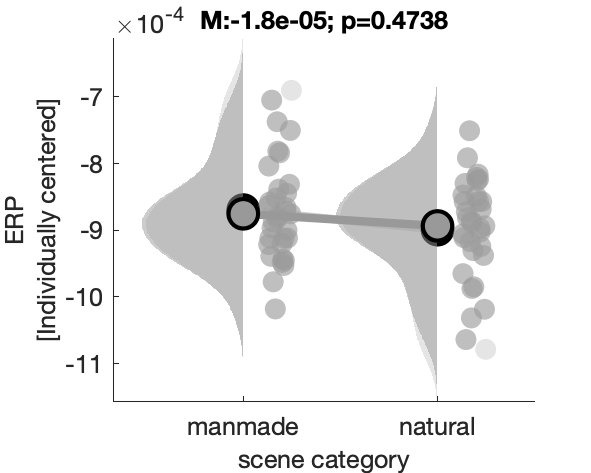
Figure 1d:
Topography around N1 trough:
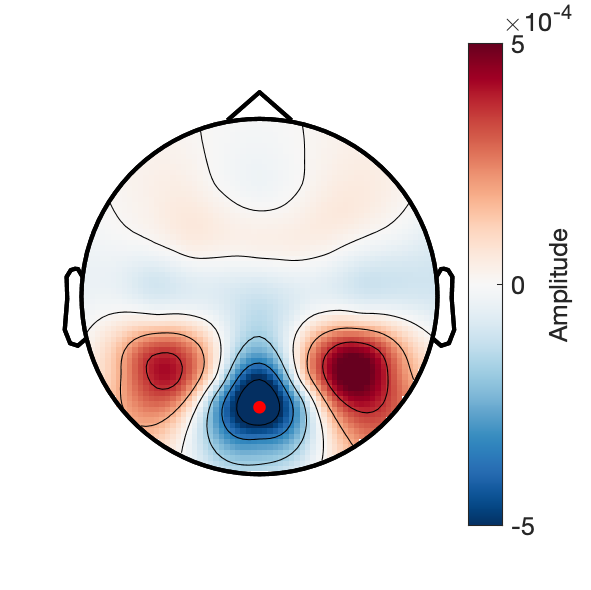
c1_taskPLS_novelty_frontal_erp
Assess effect of image novelty on fronto-central voltage.
Figure 2a:
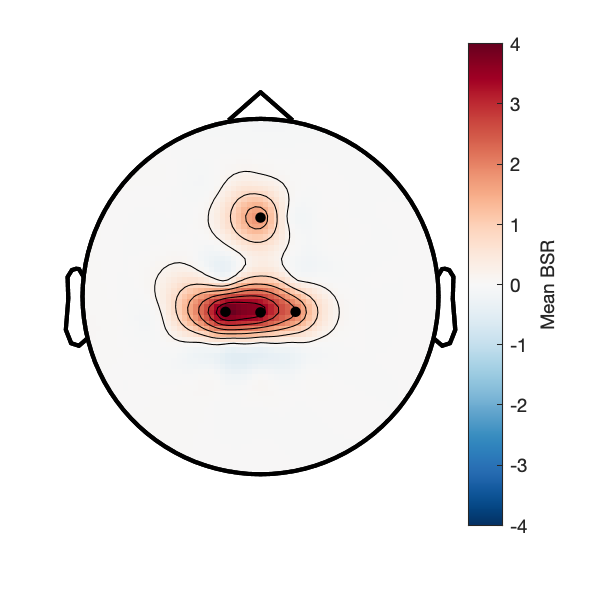
Figure 2b:
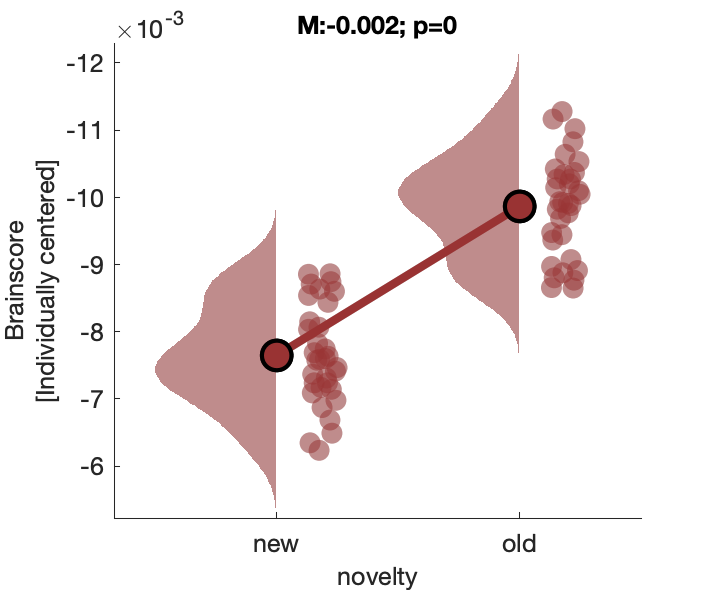
Figure 2c:
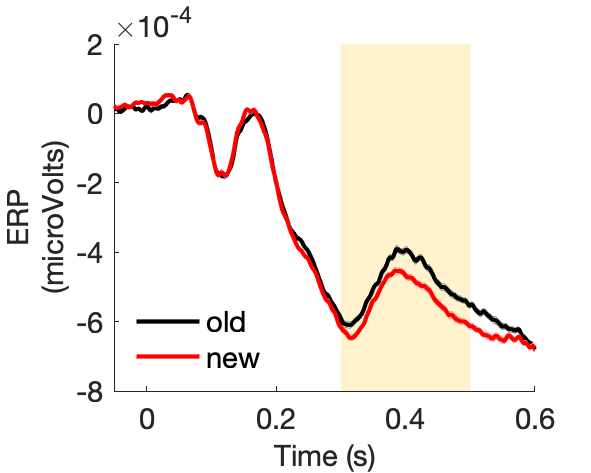
Figure 2d:

c2_taskPLS_novelty_frontal_theta
Assess effect of image novelty on fronto-central theta power.
Figure 3a:
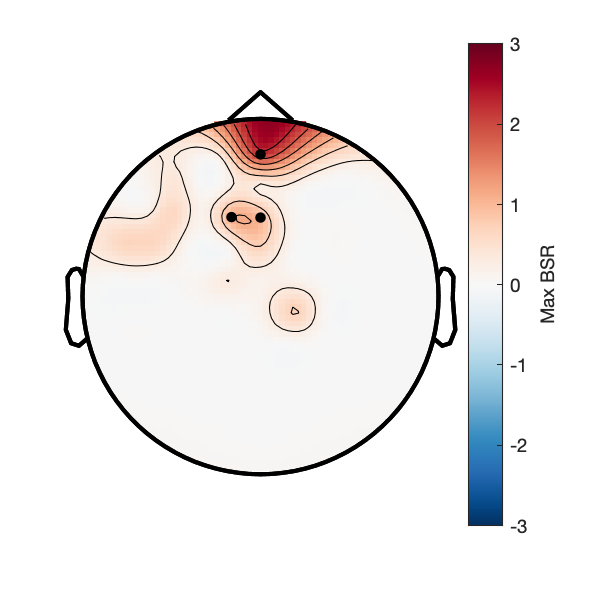
Figure 3b:
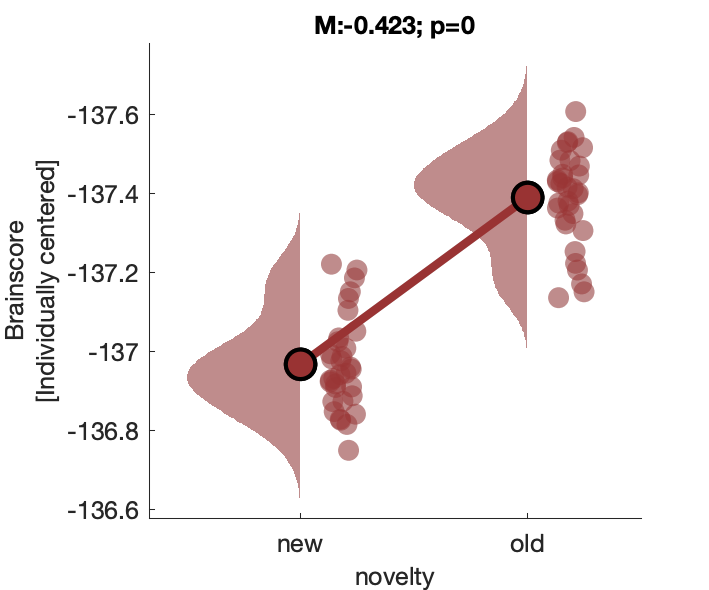
Figure 3c:
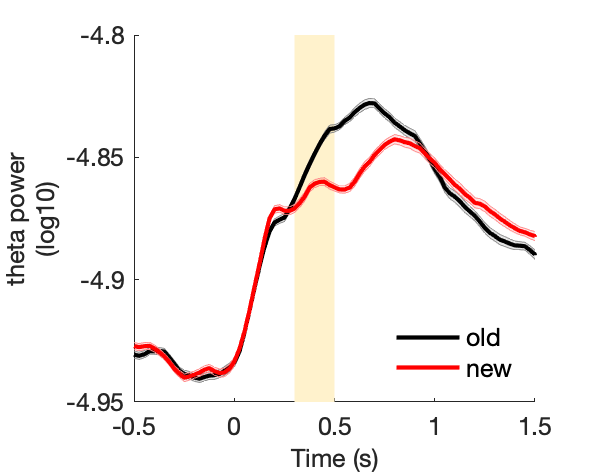
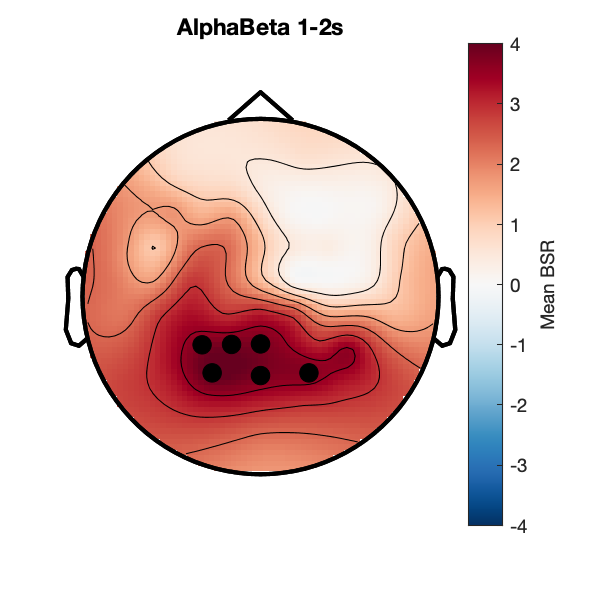
c3_taskPLS_novelty_posterior_alpha
Assess effect of image novelty on posterior alpha power.
Figure 4:
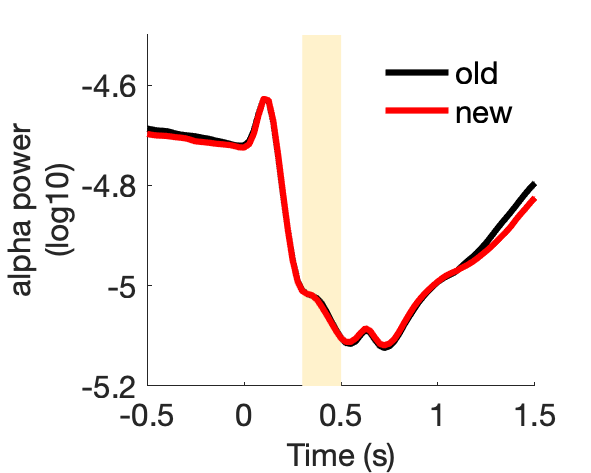
d1_taskPLS_recognition_erp
Assess effect of successful 'old' recognition on voltage.
Figure 5a:
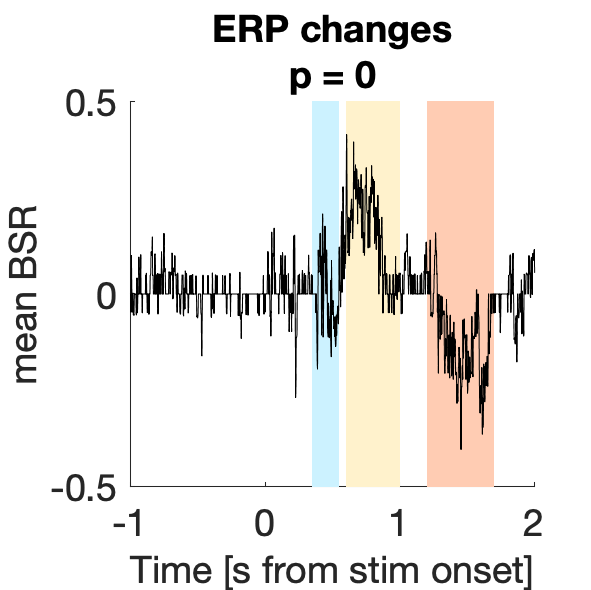
Figure 5b:
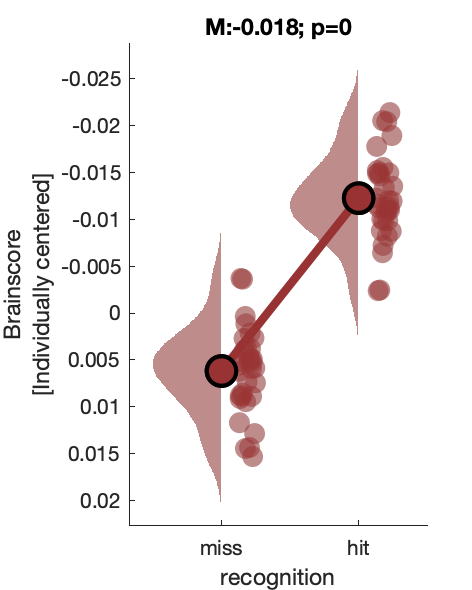
d2_taskPLS_recognition_erf
Assess effect of successful 'old' recognition on spectral power.
Figure 6a:
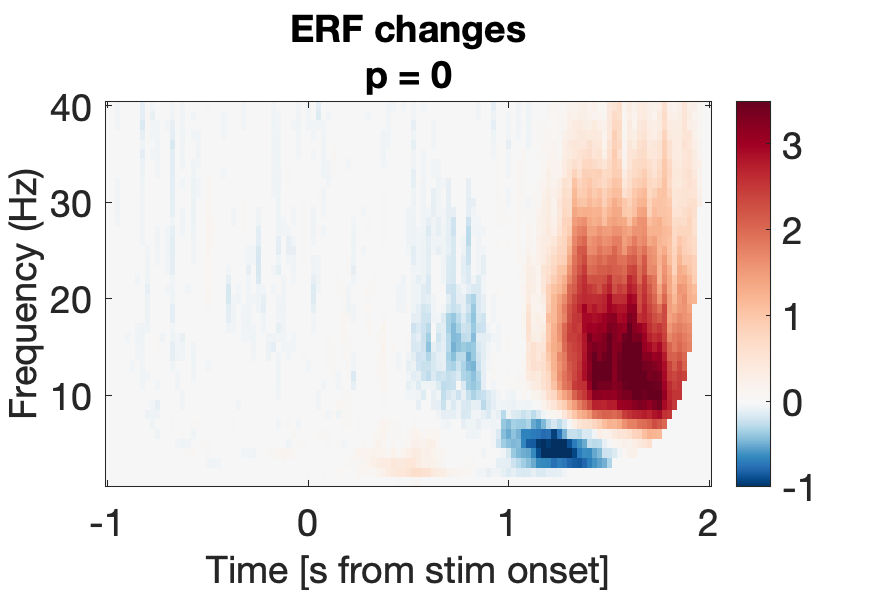
Figure 6b:
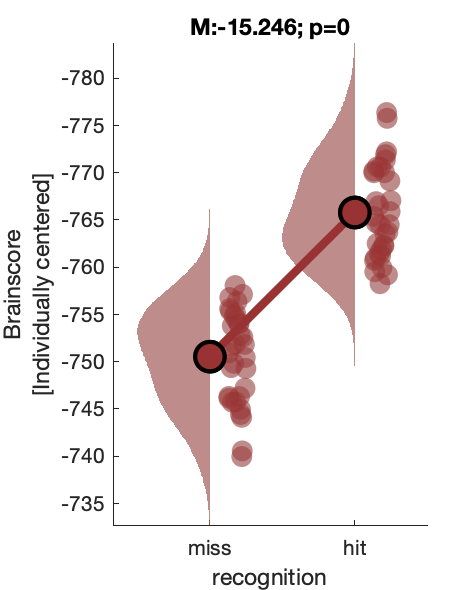
Figure 6c:
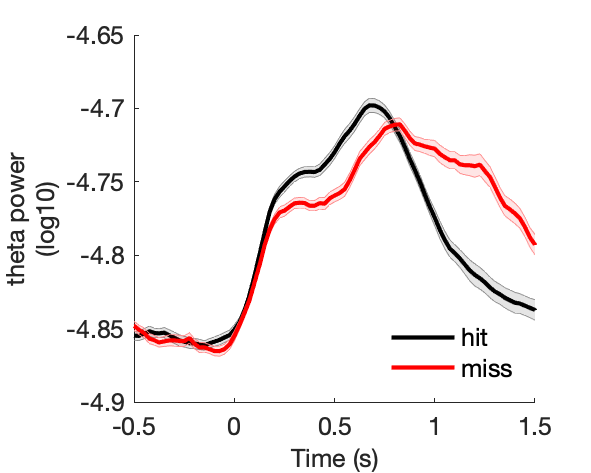

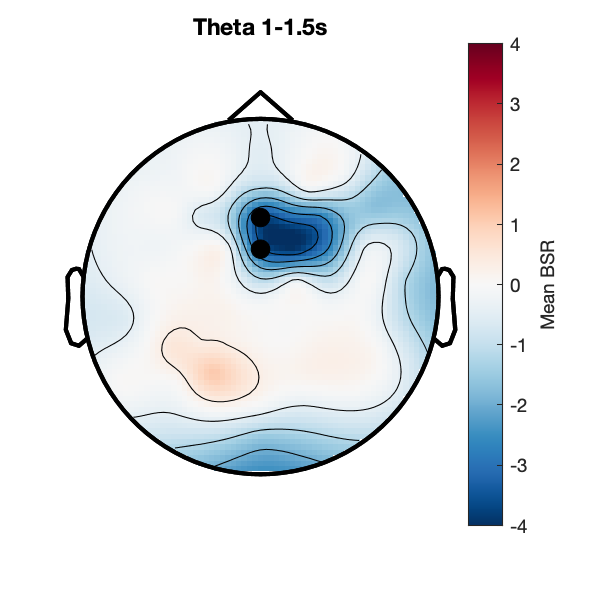
Figure 6d:
e1_taskPLS_memory_erp
Assess effect of subsequent memory on voltage.
e2_taskPLS_memory_erf
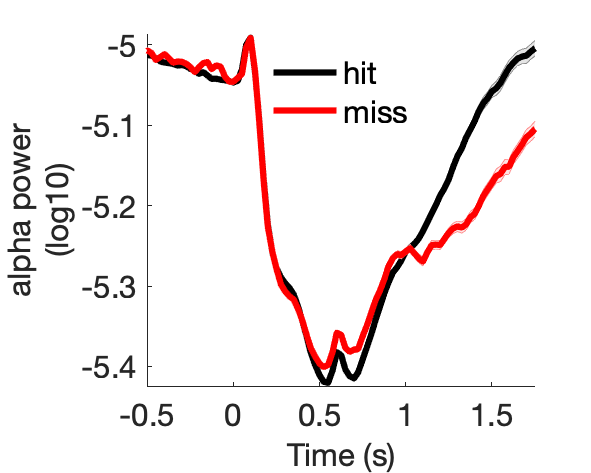
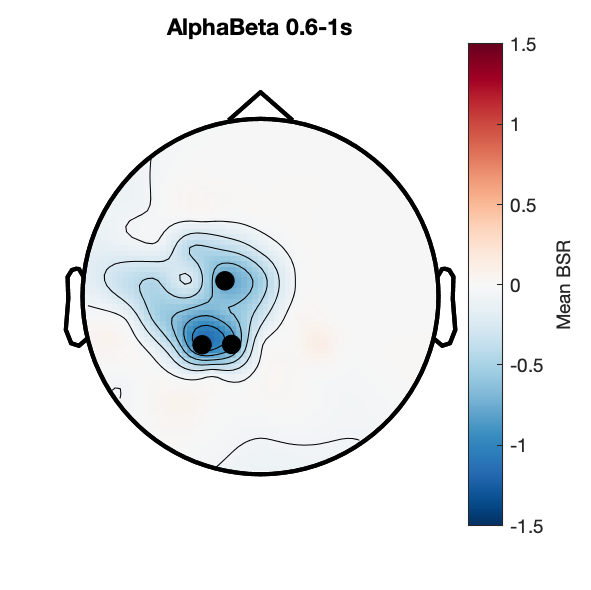
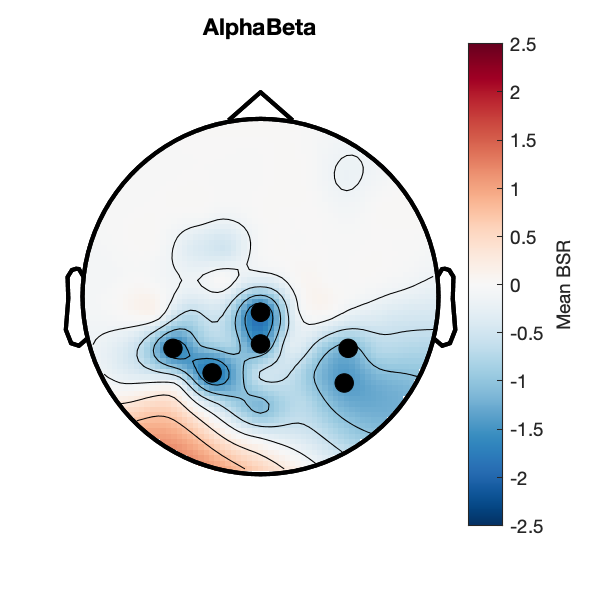
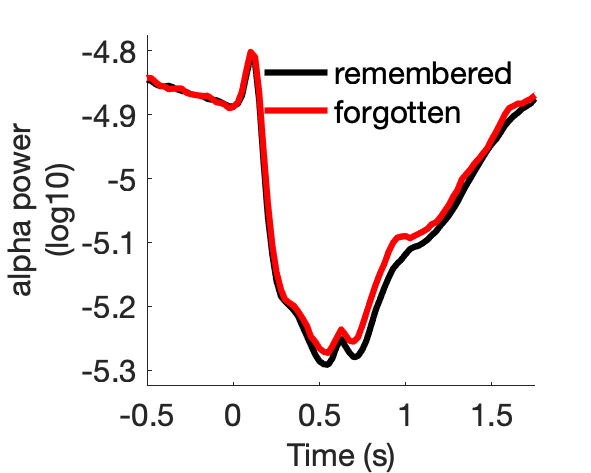
Assess effect of subsequent memory on spectral power.
Figure 7a:
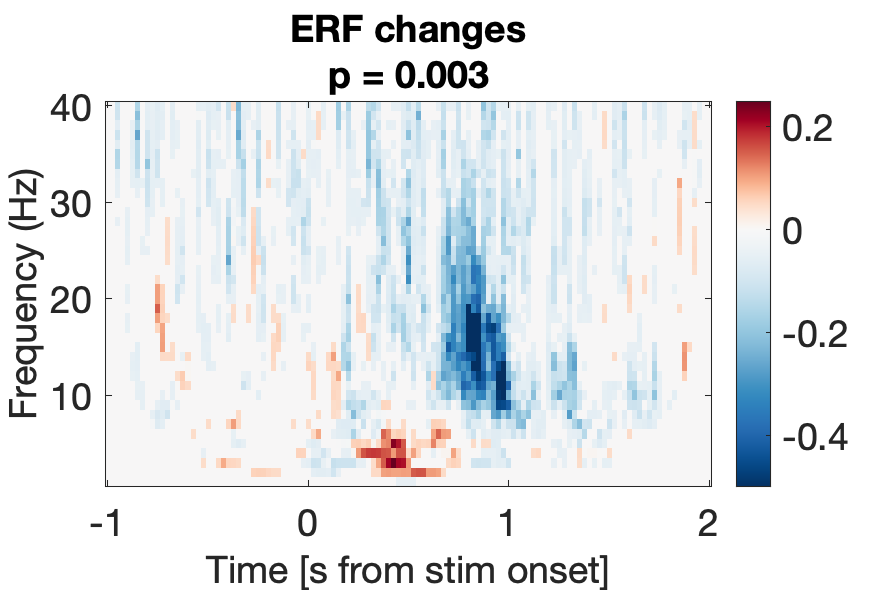
Figure 7b:
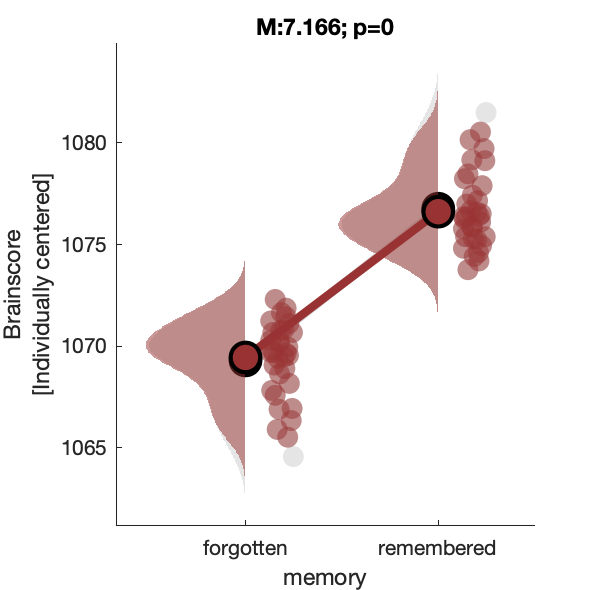
Figure 7c:
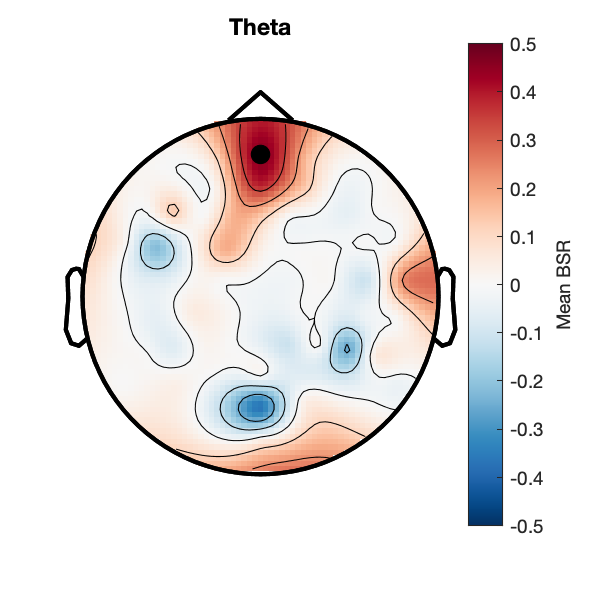
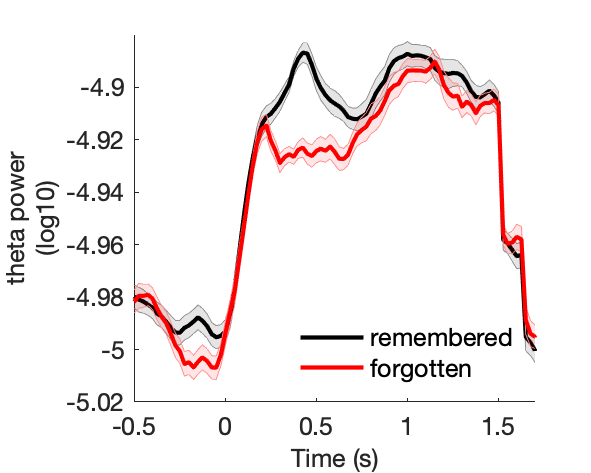
Figure 7d:
DataLad datasets and how to use them
This repository is a DataLad dataset. It provides fine-grained data access down to the level of individual files, and allows for tracking future updates. In order to use this repository for data retrieval, DataLad is required. It is a free and open source command line tool, available for all major operating systems, and builds up on Git and git-annex to allow sharing, synchronizing, and version controlling collections of large files. You can find information on how to install DataLad at handbook.datalad.org/en/latest/intro/installation.html.
Get the dataset
A DataLad dataset can be cloned by running
datalad clone <url>
Once a dataset is cloned, it is a light-weight directory on your local machine. At this point, it contains only small metadata and information on the identity of the files in the dataset, but not actual content of the (sometimes large) data files.
Retrieve dataset content
After cloning a dataset, you can retrieve file contents by running
datalad get <path/to/directory/or/file>`
This command will trigger a download of the files, directories, or subdatasets you have specified.
DataLad datasets can contain other datasets, so called subdatasets. If you clone the top-level dataset, subdatasets do not yet contain metadata and information on the identity of files, but appear to be empty directories. In order to retrieve file availability metadata in subdatasets, run
datalad get -n <path/to/subdataset>
Afterwards, you can browse the retrieved metadata to find out about
subdataset contents, and retrieve individual files with datalad get.
If you use datalad get <path/to/subdataset>, all contents of the
subdataset will be downloaded at once.
Stay up-to-date
DataLad datasets can be updated. The command datalad update will
fetch updates and store them on a different branch (by default
remotes/origin/master). Running
datalad update --merge
will pull available updates and integrate them in one go.
Find out what has been done
DataLad datasets contain their history in the git log.
By running git log (or a tool that displays Git history) in the dataset or on
specific files, you can find out what has been done to the dataset or to individual files
by whom, and when.
More information
More information on DataLad and how to use it can be found in the DataLad Handbook at handbook.datalad.org. The chapter "DataLad datasets" can help you to familiarize yourself with the concept of a dataset.