On Friday, November 22, 2024, between 06:00 CET and 18:00 CET, GIN services will undergo planned maintenance. Extended service interruptions should be expected. We will try to keep downtimes to a minimum, but recommend that users avoid critical tasks, large data uploads, or DOI requests during this time.
GIN is mainly a web-accessible repository store of your data based on git and git-annex that you can access securely anywhere you desire while keeping your data in sync, backed up and easily accessible from within or outside the lab.
Git, probably the most famous open version control system, is excellent at dealing with smaller files and projects as it specializes on tracking changes in text files. This makes git quick, efficient and easy to work with providing flexible workflows and data integrity. However, working with large binary (non-text) files can be quite challenging. This is where git-annex comes into play. It hooks into git using links and tracks the big binary files elsewhere! However, using this platform independently can also be challenging.
Therefore, we developed GIN combining the two while trying to spare you the nitty-gritty details. But before we come to the details let us give an example to explain what is happening.
The card catalogue at Manchester Central Library
Example
In the old days, before computers invaded our everyday life, the task of finding a book in a large library was not exactly straightforward. What many libraries offered was a card catalog for their collection. This was a collection of information about each and every book, including their physical location, written on separate paper cards, which were in turn placed in order in a catalog drawer. One could nicely search such catalogs, and they even came with different sorting orders. What is important is that a book's title, authors, publisher, keywords and so forth (its bibliographical information, or, in modern terms, the book metadata) and the book itself were disentangled! This made and actually still makes many things easier.
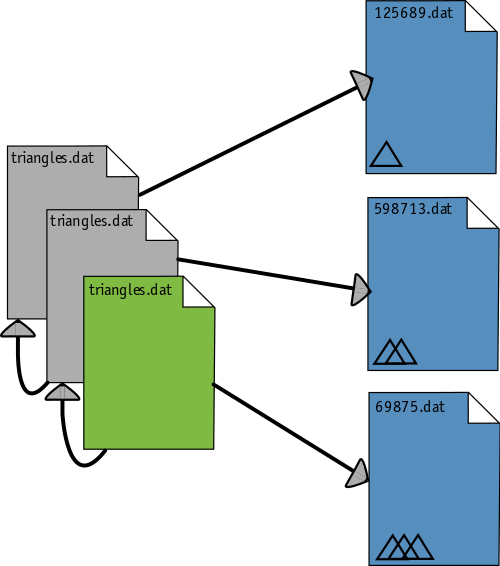
Back to GIN
It is the same with big files in GIN. GIN takes your file meta-data, writes it down in a replacement file, puts that file to where your original file was, and keeps a reference to the location of the original file content (see I managed to put the word file 6 times into one sentence!). In most cases, you won't even notice the difference! What's cool is that the new location of the file content (basically its new name) depends on the content itself, which in turn means that no one can change that content without leaving a trace! Basically, the file location and the reference to the location changes whenever the file is updated, while the original content stays where it is. So you get informed that the file has changed, you get a new content location, and you can still go back to the original version.
In our library example, such an updating is equivalent to the following scenario: As soon as a new version of a book comes rolling in, the librarian updates the catalog card with the location of the new book, while still keeping the old book around as well as a reference to its location!
The central concept in GIN data organization: There are two layers. To the left are the files you most probably see in a folder. They only contain metadata and point to the file content (right side). You can step through the history of those pointer files (links) and get back old data - each of them represents a point in time. The left side is like the card catalog in old style libraries, whereas the right side is like the books on their shelves in a library magazine. Collaborators can download the left side first and request the right side on demand!
Can old file version be removed?
Yes. If you really, really have to, you can drop an old file version. However, the reference that there once was another version will always kept for referential integrity (and because maybe the file could be found somewhere else if need be)! In the library example: sure you can trash old books, but do you really want to? And even if you do, the librarian will remember that there were those old versions and keep a reference in his catalog!
Further Advantages
While it is already nice that you are safe from accidental or malicious data change, on a day to day basis that is probably more of a side issue. But the GIN approach has more advantages.
A main feature is that you can download the file metadata (the library catalog cards) without the real data. That is great because metadata is small, whereas real files tend to be big or even gigantic. Most people do not need all the big files at once (as one typically doesn't read an entire library), and for them, it makes total sense to just get the information that those data exist. They will then download the content only on demand. GIN makes this easy for you!
Another nice feature is that you can travel back in time and retrieve an older version of your data. For example, the data version for which you know that your analysis worked the last time. This is not only true for big files but also for small text files like data analysis scripts. You can even keep a reference to a working combination of big files and scripts. For example, a combination of which you made a specific plot or something. All of this is cryptographically safe and uniquely identified. At least as long as you don't stop tracking files with GIN (which is probably equivalent to killing the librarian and shredding his catalog) you can always go back!
But really how?
Well, we use a combination of tools called git and git-annex that basically do all the magic (git is a pretty clever catalog and annex basically is a librarian moving around books and noting their bibliographical data in the catalog). You can even use them directly if you want!
For most cases, however, we provide you with a tool that takes care of a lot of details in the background. It's like a servant that visits the library for you and does all the searching in the index as well as the talking to the librarian!
Achilleas Koutsou edited this page 4 years ago
Delete Page
This will delete the page "GIN Advantages Structure". Please be certain.