# Motor evoked potentials for multiple sclerosis: A multiyear follow-up dataset.
# Introduction
Multiple sclerosis (MS) is a chronic disease affecting millions of people worldwide. The signal conduction through the central
nervous system of MS patients deteriorates. Evoked potential measurements allow clinicians to monitor the degree of
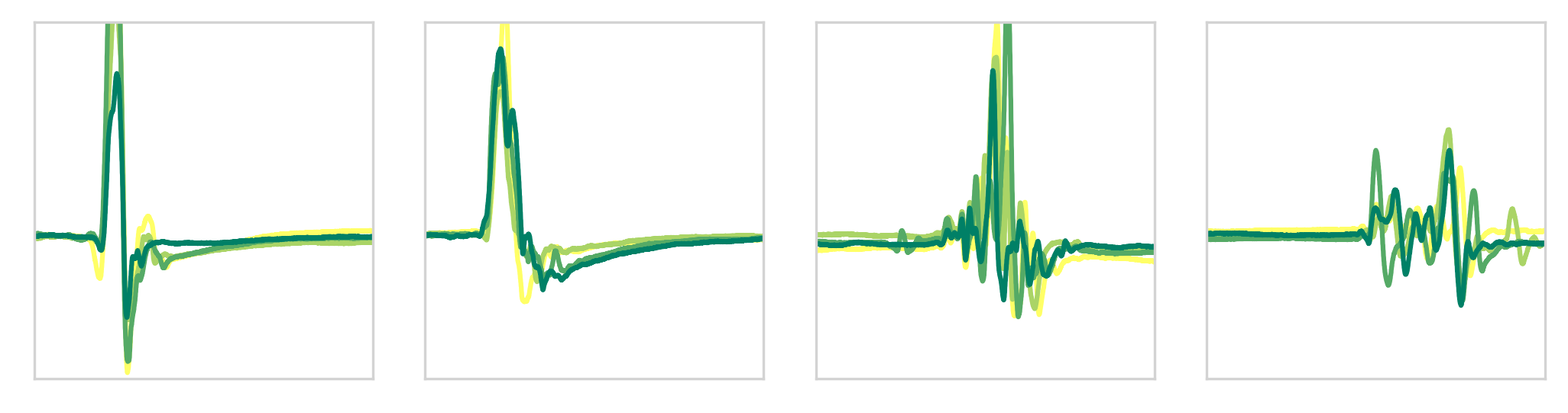
deterioration and are used for decision support. We share a dataset that contains motor evoked potential (MEP) measurements,
in which the brain is stimulated and the resulting signal is measured in the hands and feet. This results in time series of 100
milliseconds long. Typically, both hands and feet are measured in one hospital visit. The dataset consists of 5586 visits of
963 patients, performed in day-to-day clinical care over a period of 6 years. The dataset consists of approximately 100,000
MEP. Clinical metadata such as the expanded disability status scale, sex, and age is also available. This dataset can be used
to explore the role of evoked potentials in MS research and patient care. It may also be used as a real-world benchmark for
machine learning techniques for time series analysis and predictive modelling.
# Usage
## Downloading the dataset
There are a few ways to download the dataset ([data/mep_dataset.zip](data/mep_dataset.zip)). Since it is a fairly small filesize (~300MB), it can just be downloaded through the web interface.
Or from the commandline:
```bash
wget https://gin.g-node.org/JanYperman/motor_evoked_potentials/raw/master/data/mep_dataset.zip
```
Alternatively, you may clone the repository to your local machine, which will also include the dataset:
```bash
git clone https://gin.g-node.org/JanYperman/motor_evoked_potentials.git
```
For more ways of accessing the data, please refer to GIN's [FAQ](https://gin.g-node.org/G-Node/Info/wiki/FAQ+Troubleshooting#how-can-i-access-the-data).
## Structure
The dataset itself is stored in [data/mep_dataset.zip](data/mep_dataset.zip). The general structures is as follows:
* __patient.csv:__ Contains the records for the various patients.
* __visit.csv:__ Contains the records for the various visits.
* __test.csv:__ Contains the records for the various tests.
* __measurement.csv:__ Contains the records for the various measurements.
* __edss.csv:__ Contains the records for the various edss measurements.
Besides these files the dataset also contains textfiles for each of the actual time series. The filenames of these files contain a unique identifier which can be used to link back to the column "timeseries" in the measurement.csv file. Some code to automate this linking (in Python) is included in [code/create_df_from_portable_dataset.py](code/create_df_from_portable_dataset.py).
More details about specifics fields can be found in the dataset descriptor.
## Getting started
It is highly recommended to have a look at the included [code/jupyter notebook](code/sample_use_case.ipynb) to familiarize oneself with the dataset.
It includes a sample use case and goes over how to work with the dataset.
To run the jupyter notebook a few Python packages are required:
* Pandas
* Numpy
* Matplotlib
* Scipy
* Scikit-learn
* Tqdm
* Jupyter
For example in anaconda this could be achieved using:
```bash
conda create --name mep python=3 pandas numpy matplotlib scipy scikit-learn tqdm jupyter
```
which creates an environment called "mep" that contains the required packages.
# License

This work, including the provided code, is licensed under a Creative Commons Attribution 4.0 International Public License.
See [LICENSE](LICENSE) file for the full license.