EL1000
Requesting access to the data
The procedure to request access to the data can be found here.
Gaining access to the data
Once your project has been approved, the technical advisor will ensure your access to the data sets. Please note that you may not have been allowed access to all of the corpora, either because data donors declined, or because you are not a Homebank member.
Data (including .its and metadata) have been formatted using the ChildProject package; for an overview of the formatting and structure, see this introduction. We strongly encourage you to build on this (i.e., do not move data around, do not make other copies), which will allow you to maintain compatibility with others and increase reproducibility. For an example of how to set up an analysis that relates to data sets like this one, see this example or this one.
To access the data, you'll need to:
- Create an account on https://gin.g-node.org/user/sign_up
- Give your username to the technical advisor
- Follow the instructions to install the ChildProject package and DataLad
- Wait until you have received confirmation from the technical advisor, that you now have access. Then, follow instructions below.
Re-using EL1000 datasets
Requirements
You will first need to install the ChildProject package as well as DataLad. Instructions to install these packages can be found here.
Configuring your SSH key on GIN
This step should only be done once for all.
- Copy your SSH public key to your clipboard (usually located in ~/.ssh/id_rsa.pub). If you don't have one, please create one following these instructions.
- In your browser, go to GIN > Your parameters > SSH keys.
- Click on the blue "Add a key" button, then paste the content of your public key in the Content field, and submit.
Your key should now appear in your list of SSH keys - you can add as many as necessary.
Installing datasets
First, clone the EL1000 superdataset:
datalad install -r git@gin.g-node.org:/LAAC-LSCP/EL1000.git
cd EL1000
To get data from any of the EL1000 datasets (e.g.: kidd), cd into it, then run the setup script.
cd kidd
datalad run-procedure setup
If you would like to claim access to the confidential files as well, do the following instead (notice the --confidential flag):
cd kidd
datalad run-procedure setup --confidential
Note: you may not have been allowed access to all of the corpora, either because data donors declined, or because you are not a Homebank member. If you think you should have access to more corpora, please get in touch with the technical advisor.
Getting data
You can get data from a dataset using the datalad get command, e.g.:
datalad get annotations # get all files under annotations/
Or:
datalad get . # get everything
You can download many files in parallel using the -J or --jobs parameters:
datalad get . -J 4 # get everything, with 4 parallel transfers
For more help with using DataLad, please refer to our cheatsheet or DataLad's own cheatsheet. If this is not enough, check DataLad's documentation and Handbook.
Fetching updates
If you are notified of changes to the data, please retrieve them by issuing the following commands:
datalad update --merge
datalad get .
Removing the data
It is important that you delete the data once your project is complete.
This can be done with datalad remove:
datalad remove -r path/to/your/dataset
Data description
Data documentation
Datasets are structured according to the ChildProject package standards detailed here.
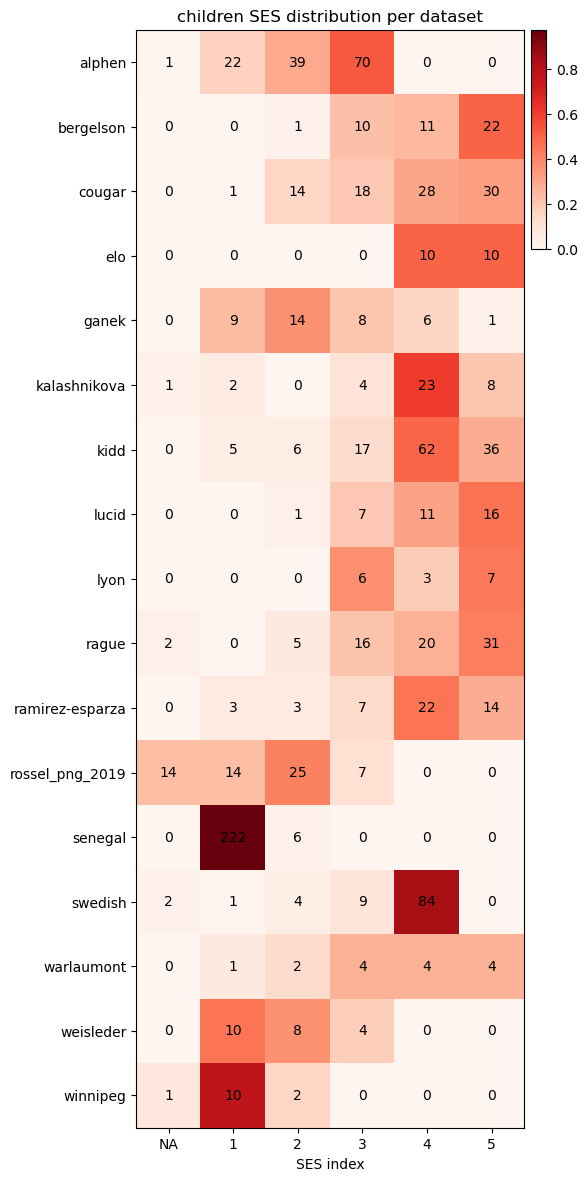
Participants


The matrix of how many children are exposed to language X in corpus Y can be found in documentation/languages.csv.
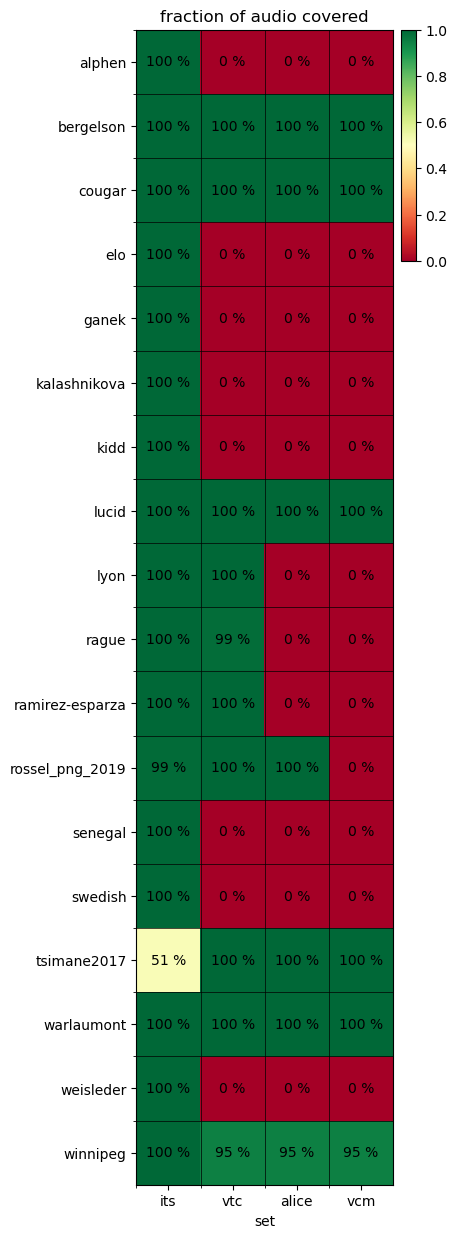
Available annotations
Derived datasets
- metrics: metrics derived from ACLEW and LENA annotations.
- reliability: reliability estimations for ACLEW and LENA annotations based on manual annotations.
Maintainers
The EL1000 package
In order to maintain EL1k datasets (e.g. to export metadata from .its annotations, or to import annotations),
the EL1000 package is needed.
It can be installed with pip with the following command:
pip install git+ssh://git@gin.g-node.org:/LAAC-LSCP/tools.git --upgrade
How to import new datasets
Instructions to import new datasets can be found here.

